I’ve done this datavis on arab spring with processing + inkscape and here’s Pablo’s comments
Categories
PageOneX Development Status
We are now is so close to the first Version 0.1, which will basically give the user the following features; to be able to create an account and creating a Thread, with basic info; name, start date, end date (in the same month, just for alpha version), description, choosing and number of newspaper, and Topics to code with it and for each topic the user can add a color and description.
Then user start to code scraped images (opened issues) with selected topics, the color of highlighted area will be based on the topic color, maximum number highlighted areas for alpha version is two, and if the user want to add any other highlighted areas, the system will prompt the user with the option to clear the current highlighted areas or skip adding other highlighted area, after that the display, it’s not finished yet.
Here’s a UI – first drafts and Some of opened issues
Categories
User interface: first drafts
User interface drafts from some weeks ago
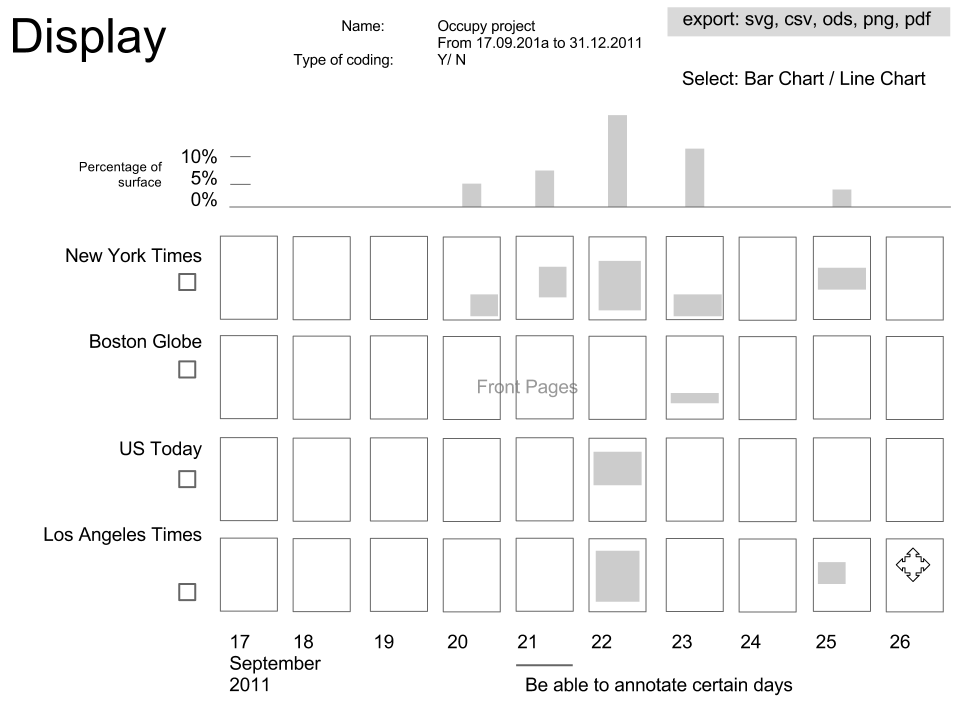
Display: being able to select one/various newspapers. It modifies on the fly the graphic. able to click on a front page to see it bigger two ways of zooming in: just a front page and the entire graphic. Enable edit mode. Example: http://gigapan.com/gigapans/106802 
Code: Possibility to click and enlarge to zoom in and read. We need a full screen view, and zoom in-out to be able to read the news. Drag and select the area with the mouse. Attached to a grid to low resolution of selection. It will make easier the intercoder reliability. The areas will have transparency, similar to “multiply” filter in gimp or photoshop. 
New Thread: able to “open day” for ongoing events. 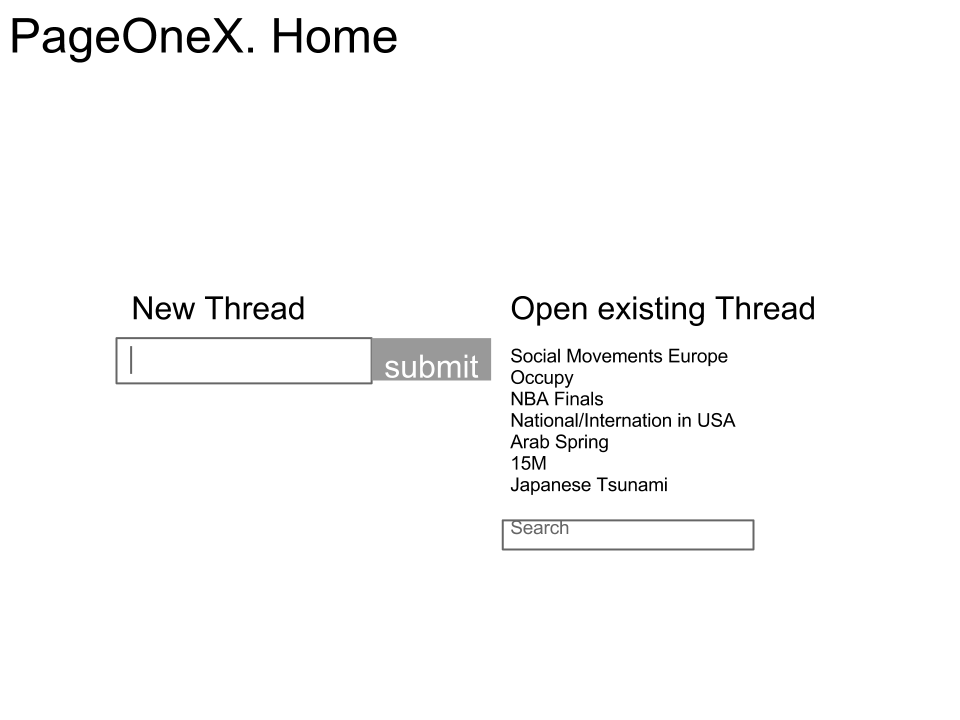
Home: Able to open new thread, login, open existing thread, search thread
First previews form the Ruby On Rails application:

Display 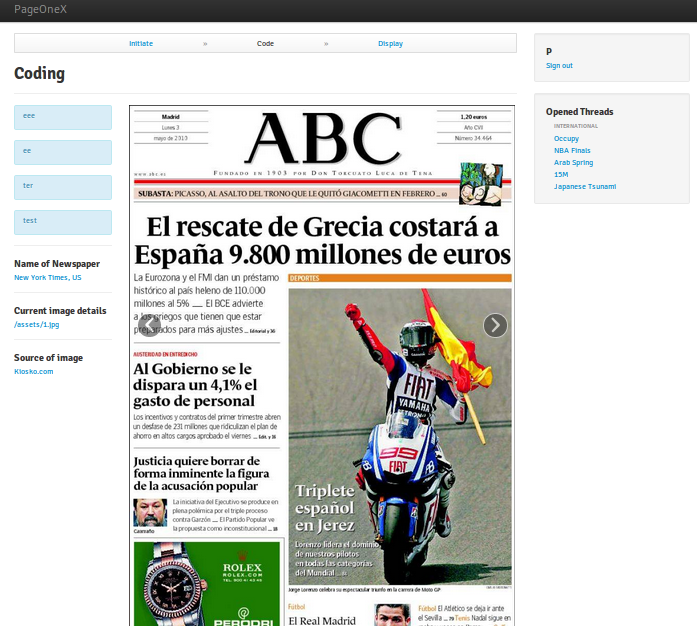
Code 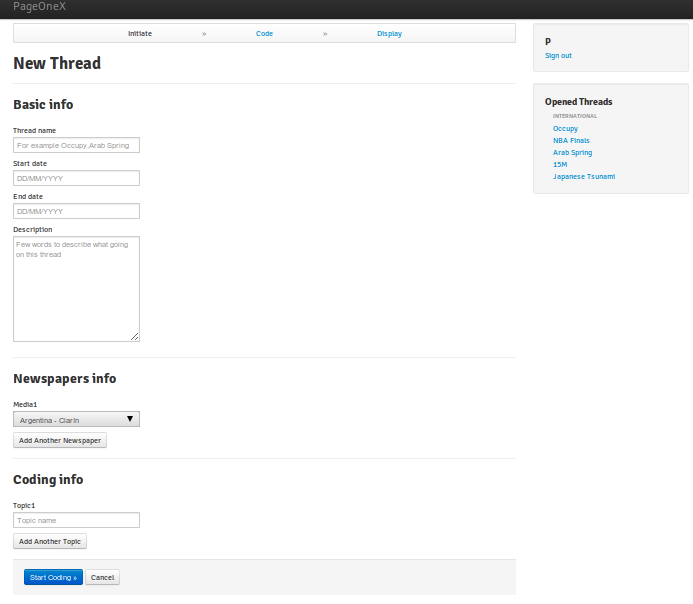
new Thread 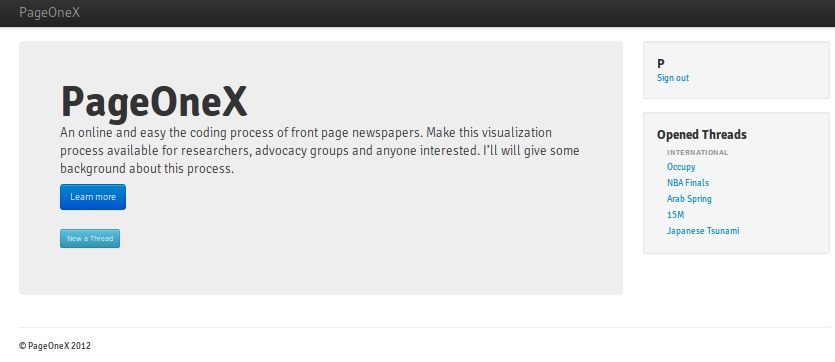
Home
Rporres was visiting Cambridge last week, and after listening to one of the online meetings, he decided to jump in the project. By night he had finished the script for grabbing all the newspapers that are available in Kiosko.net. We will need this list soon
You can check the code at https://gist.github.com/2970558 or the output (a csv file with the name, friendly url name, coauntry and country code of all the 377 newspapers) at http://brownbag.me:9001/p/pageonex-kiosko-newspaper-names. It’s written in Perl.
Ahmd had started another similar one in Ruby, but we put it on hold for the short term.
Thanks Rafa for your help!
After the user creates a thread, he selects starting date and end date which could span on more than one month. The problem is that the scraping script works on one month at a time, because I’ve found a difficulty to write a method that can take the start and end date in different months and calculated the number of days between them. Because of that the days at each month changes from one year to another, that doesn’t mean it’s impossible to do, but it will add some complexity which can be avoid by, asking the user for starting day and end day for each month individuality, and run the script for each individual month.
So any suggestions on how to make this part more easy and conveniente?
issues_dates is the method which calculate the dates and return an array of the dates in this format “YYYY/MM/DD”
Look at the code of this script at https://gist.github.com/2925910
Categories
PageOneX initial data model
Brief description of the data models
{kind=link}
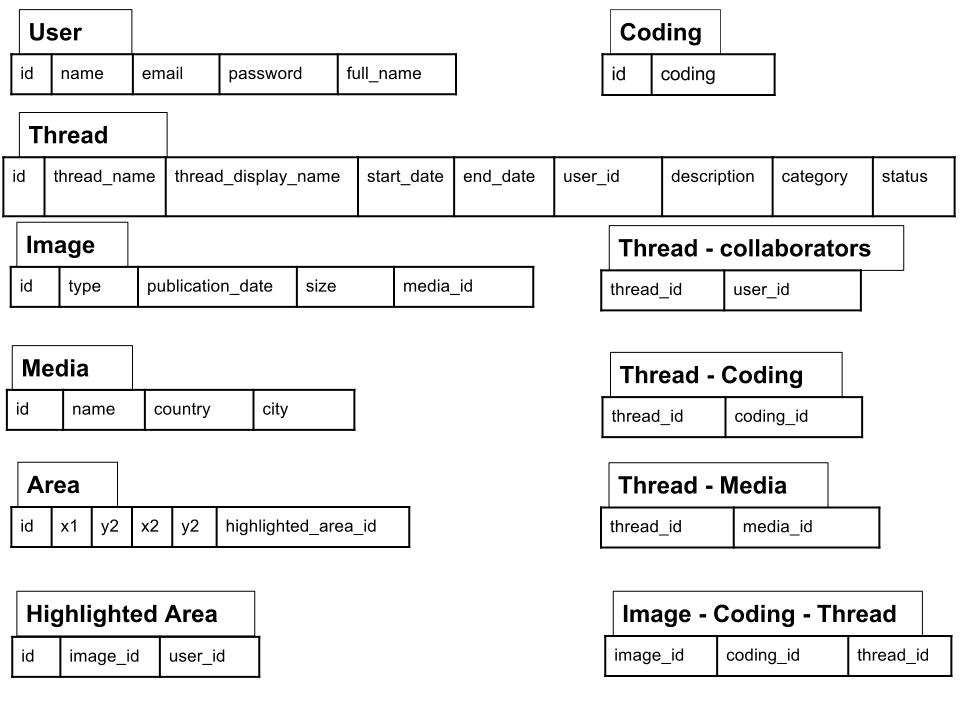
1. User: each user that uses the tool to build a visualization should create an account.
2. Thread: this is the main model which represents the visualized data with its related information:
- thread_name: url-friendly
- thread_display_name: full name
- user_id: creator of thread
- category: predefined words / or better use tags / or both
- description: short text
- status: open thread will add newspapers every date (will change end date) but should have a limit
3. Image: represent a snapshot of a media to code, it could be a newspaper front page or a magazine cover or even an online newspaper home page or a blog.
4. Media: different media can be represent, and identified by their country and city. It will be extended in the future to cover more different media types.
5. Highlighted Area: this model used to store the coordination of the highlighted area(s)
Questions: Non rectangular news: http://img.kiosko.net/2012/06/11/us/newyork_times.750.jpg how to id?
{kind=link}
Possible solution:
- Multiple area selection
- Select and remove a part of the selection after selecting the main article
6. Area: holds the coordinates of each specified area.
7. Coding: stores the coding that the user have created.
Other models are for association between the models.
I’ve made some changes to the script to scrape from different sources (http://kiosko.net, http:/nytimes.com, http://elpais.com) and other sources can be added easily, for each source there are two methods, build_source_issues and save_source_issues, the first method is to construct the URI of the issue image based on some pattern which different from source to another, and the other method is to scrape the images and save them on the disk in their specific folders. I’ve wrote some comments to clear some parts of the code.
Note, to scrape from specific source you should comment the others as you can see in the code, for example to scrape from New york Times you should un-comment line 15 and line 32 and comment line 14 and line 31, and also if you want to run the script on https://scraperwiki.com/ you should comment line 3 and don’t try to scrape from elpais because scraperwiki don’t have “RMagick” gem installed.
Information about sources used in the script
Date limits: there are no specific starting date, scraping starting from 2008, but most of the newspapers exist starting from 2011, the script is able to scrape from [2008-2012 ]
Image resolution: [750×1072]
Date limits: first issue available date is 2002/01/24
Image resolution: [348×640] the resolution is not enough for coding!
Date limits: first issue available date is 2012/03/01
Image resolution: [765×1133] the resolution of produced images can be changed!
Script on Github
Ahmd has been working on a scrapper in Ruby for the front Pages at Kiosko.net
I’ve finished the scraping script, and it’s public on https://gist.github.com/2925910 to run the script just pass the file to ruby [ruby scraper.rb] and it will generate the folders (the directories is set for Linux, if you are on Windows you should modify them first), download the images(you can change the variable values in the get_issues method to get different newspapers), and write the log to stdout.
Check the script below.
I’ve also contacted Newseum to see if their “only today” front page data base is avaible for PageOneX.
Script to scrape front pages images of newspapers form kiosko.net
June 11th 2012. 10am-12.45pm EST
People: Ahmd + Pablo
Check the live notes of the meeting at http://brownbag.me:9001/p/120611pageonex
Categories
PageOneX, ready steady go!
Crossposting from numeroteca.org.
View this datavis full size at gigapan.
Today’s post is to present the tool we are building this summer: PageOneX. The idea behind is to make online and easier the coding process of front page newspapers. Make this visualization process available for researchers, advocacy groups and anyone interested. I’ll will give some background about this process.
How things started
Approximately one year ago I started diving in the front page world. It was days after the occupations of squares in many cities from Spain, and I was living in Boston. I made a front page visualization to show what people was talking about: the blackout in the media about the indignados #15M movement. You can read more about Cthe story in the ivic Media blog. Since then I’ve been making more visualizations around front pages of paper newspapers, testing different methods and possible ways to use them. I’ve also made a tool, built in Processing, to scrap front pages from kiosko.net and build a .svg matrix.
- Gallery of different twitter-newspaper visualizations. http://numeroteca.org/cat/frontpage-newspaper/
- Post: Analyzing newspapers’ front pages to interpret the Mainstream Media ecology.
http://civic.mit.edu/blog/pablo/analyzing-newspapers-front-pages - Presentation: Approach to a User interface. http://www.slideshare.net/numeroteca/arab-spring-spanish-recolution-and-occupy-movement-mainstream-media-vs-social-media-coverage and more presentations at http://www.slideshare.net/numeroteca
- Code for the semi-automated process built in Processing: https://github.com/numeroteca/pageonex-processing
https://github.com/numeroteca/PageOneX