We’ve developed an R script to process Pageonex JSON raw area export files and regenerate charts and calculations joining different datasets. Check for more information in the repository.

We’ve developed an R script to process Pageonex JSON raw area export files and regenerate charts and calculations joining different datasets. Check for more information in the repository.
After a while we are glad to announce brand new features in PageOneX.
We developed these features last summer, but until now they have not been available in the hosted version at pageonex.com. We worked with Juanjo Bazán (@xuanxu) in this.

Until now you could export the percentage of coverage per day and paper in json and spreadsheet, now there is an extra feature that allows you to export the raw data: the extact location of every area and all its classifications (read following feature). We are starting a new project pageonexR that allows you to import your threads to R and analyse their data.
This new feature would add the capability to add extra information to drawn areas. A highlighted area could have multiple taxonomies and open fields.
Until this new release you could only classify each area with one taxonomy. For example, an area could be categorized as “International coveragae” but not as “International coverage” AND “Nigeria” AND “positive framing”. Now you can do it . This feature is only available for certain users. If you want to use it write a comment to this post. We are studying how to make this available for all the users.

You like another’s user thread: you can clone and edit it.
Before you had to erase all the areas in a front page to remove one. Now you can remove them separately and re-classify them.
Another great thing is the new containerized versions of PageOneX. Rafa Porres (@walter_burns) developed it and Rahul Bhargava (@rahulbot) deployed it at Civic media server. Thanks for your support!!
Pageonex is an open-source project. Thanks to Rafa Porres (@walter_burns) we have PageOneX ready to use in a docker container. In fact, the new containerized version is what we are using now in the production version at pageonex.com. If you don’t want to use the hosted version of pageonex at http://pageonex.com you have a few options to run it yourself. Read our documentation and choose the best option for you. We hope this helps other developers help extending the features of PageOneX.
Last January we presented PageOneX to SAGE Concept Grant Application to help us develop some new features. We didn’t get the money, but we thought it would be cool anyway to share with you the proposal. Thanks to Sam Zhang and Fernando Blatt that help us build this proposal.
If you want to help us make a better PageOneX we are now starting a new round of development, a reduced version of all the things that we had originally planned. Join the dev email list and check our road map for the following month.
This was the original proposal:
PageOneX. Visualize attention on newspaper front pages.
What it is and the problem it is looking to solve (150 word limit)
PageOneX is a Free Software tool that we designed to simplify the coding, analysis, and visualization of front page newspaper stories and media events. Even as the media ecology has been rapidly transformed by the rise of broadband Internet, mobile phones, and social media, daily print newspapers continue to be a key mechanism for organizing both public and elite attention. Communication scholars have long used column-inches or number of articles of print newspaper coverage as an important indicator of mass media attention. It involved obtaining physical copies of newspapers, coding and measurement by hand, input data into a spreadsheet. PageOneX automates and dramatically simplifies this methodology to enable researchers and media-interested public alike to analyse news coverage with an online tool.
We plan to develop new features to make PageOneX a more robust research tool:
Detailed outline of the product of prototype you are looking to build including visuals (300 word limit)

The PageOneX prototype is up and running, with 1.000+ users. Currently users can easily choose among 700+ newspapers, select a time frame, and highlight parts of newspaper front pages that feature a topic of interest (read our academic article about the tool). PageOneX automatically calculates the area dedicated to a particular topic, automating the process and making it broadly accessible online.
The tool has been used to produce visualizations for multiple peer-reviewed publications (examples at blog.pageonex.com/references).
We plan to develop new features to make PageOneX a more robust research tool. Top priority features include:
Intercoder Reliability.
Allow multiple coders to analyse the same set of front pages according to shared coding instructions, without seeing the codes applied by others, then compare values between coders to obtain a statistically valid intercoder reliability measure.
Text-based Search.
No text-based search of newspaper front page content is currently possible. We have identified several possible paths to solve this issue that will enable to analyse data at bigger scale and speed:
We are planning to use and base the development in Hadjar, Rigamonti, Lalanne, and Ingold (2004) and a working prototype by Sam Zhang using the Newseum’s database. See: Hadjar, K., Rigamonti, M., Lalanne, D., & Ingold, R. (2004). Xed: A new tool for extracting hidden structures from electronic documents. Proceedings of the First International Workshop on Document Image Analysis for Libraries (212–224). Retrieved from https://diuf.unifr.ch/people/lalanned/Articles/XedDIAL04.pdf
Cross-platform Comparison.
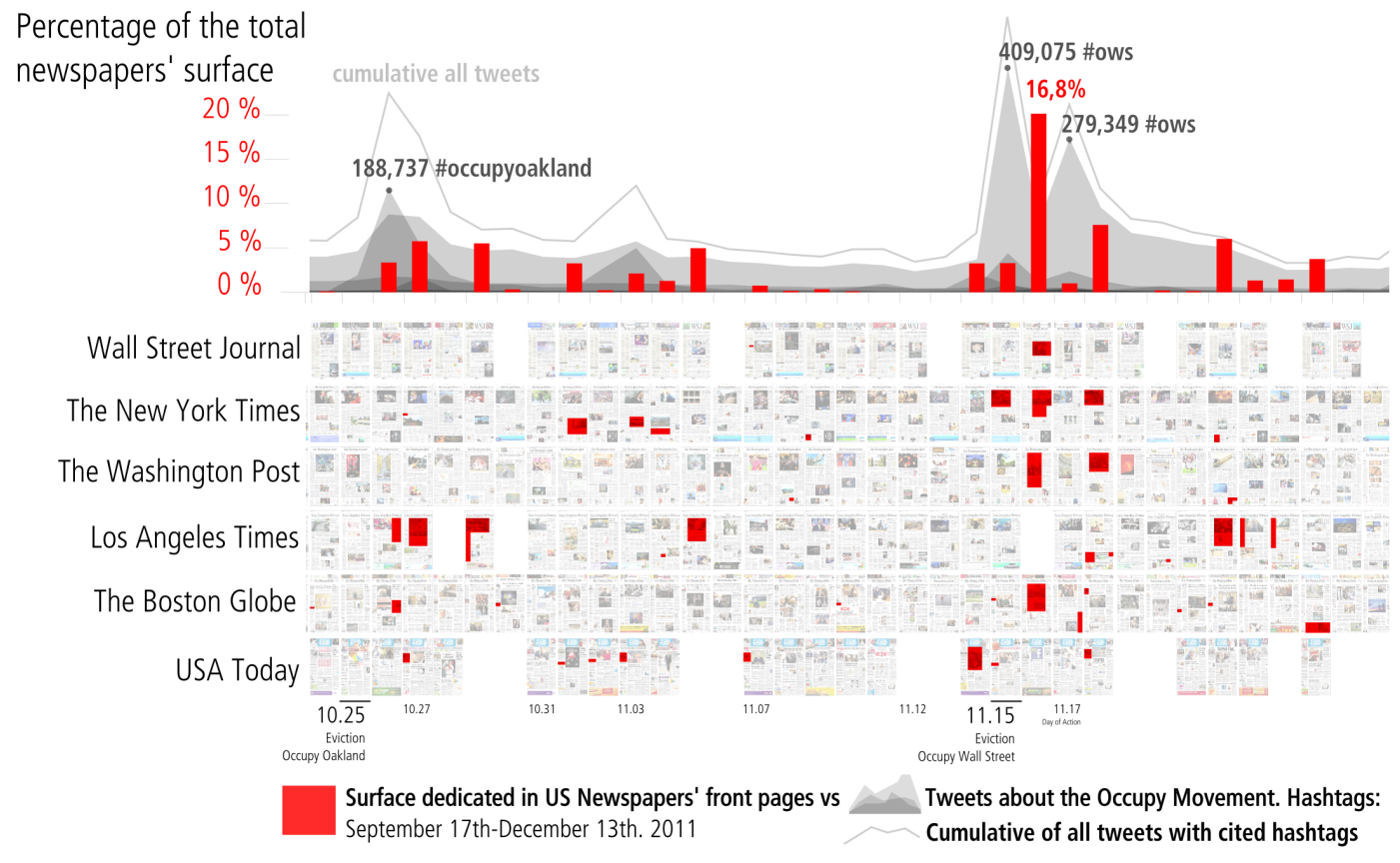
Build comprehensive cross-platform capabilities to produce analysis of media attention, and add statistical analysis of these relationships [For example, Graeff, Stempeck, and Zuckerman (2014) analysed the evolution of a story by using PageOneX alongside other metrics including Twitter updates, Google Search, bit.ly clicks, and more (link)] . We plan to integrate different sources via APIs that increasingly provide access to data: video or audio news broadcasts transcripts, closed captions (Archive.org’s archive of TV news), amount of news (MediaCloud.org) and Twitter.
Diversify Sources of Front Pages.
Currently PageOneX only uses front pages from a single source (kiosko.net). Enabling multiple sources would allow to expand its use.
Additional Feature Requests from Current Users.
Prioritizing outstanding feature requests.
Who wrote the news? News classified by author’s gender.
Website: is there a website associated with the project?
http://pageonex.com/
What else is out there and why it doesn’t fit the need (200 word limit)
There is no competitor software in the field. Scholars and data journalists who do this kind of analysis of attention on newspaper front pages either use PageOneX, or do manual data collection, coding, and visualization.
In Summer 2014 PageOneX won the 2014 APSA-ITP (American Political Science Association-information technology and politics) award for Best Software.
High level outline of your plan for development and who will be working on the product prototype (100 character limit)
April 2018
Set up communication infrastructures, development environment and protocols.
Survey to existing users. Analyse and rank requests.
Update dependencies.
May-July 2018
Intercoder Reliability (IR): development.
Text-based search (TbS): prototype.
Diversify Sources of Front Pages: development and testing.
August-October 2018
TbS: development.
IR: testing.
Cross-platform Comparison (CpC): prototype.
Users’ feature requests: development
November 2018-December 2018
TbS: testing.
CpC: development.
January-February 2019
CpC: testing.
General UX Testing. Bug fixing.
March 2019
Write grant report.
Communication.
The paper Sasha and I have been working on for quite a long time has just been published at the International Journal of Communication PageOneX: New Approaches to Newspaper Front Page Analysis. We hope it provides an useful guide and resource to the field of the newspapers front page analysis.
PageOneX: New Approaches to Newspaper Front Page Analysis
Sasha Costanza-Chock, Pablo Rey-Mazón
Abstract
PageOneX is a Free/Libre and Open Source Software tool that we designed to aid in the coding, analysis, and visualization of newspaper front pages. Communication scholars have long analyzed newspaper front pages, using column inches as an important indicator of mass media attention. In the past, this involved obtaining physical copies of newspapers, coding and measurement by hand, and manual input of measurements into a spreadsheet or database, followed by calculation, analysis, and visualization. PageOneX automates some of these steps, simplifies others, and makes it possible for teams of investigators to conduct shared newspaper front page analysis online. We review scholarship in this area, describe our approach in depth, provide concrete examples of analysis conducted by media scholars using PageOneX, and discuss future directions for research and development.
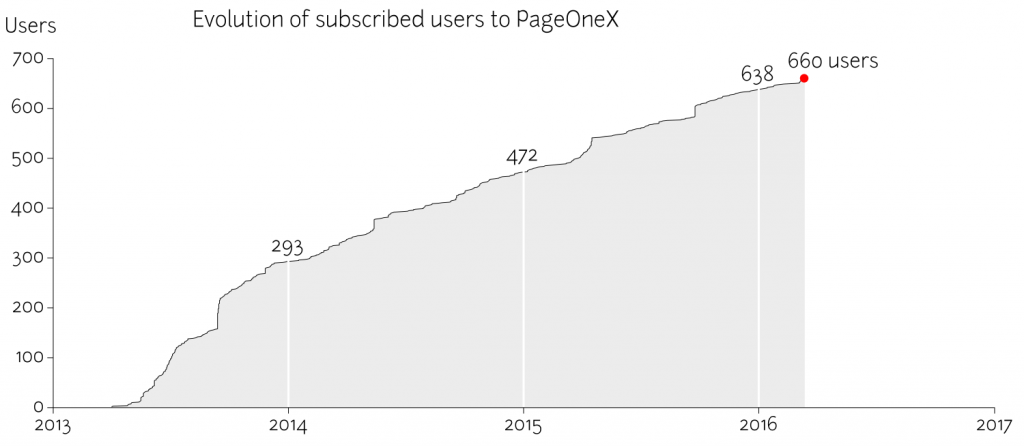
This is a first approach to study the use of PageOneX.com. The number of users is a way of measuring interaction with the site. It does not mean that all users create threads or code front pages. Why are people signing up to the site and
I should look in the periods of higher increase of subscriptions (almost vertical lines) and add that information to the graphic.

PageOneX estará en el II Encuentro de DatAnalysis15M: Modelos, analogías y análisis de las mutaciones y evolución del movimiento red 15M este viernes 19 de septiembre 2014 a las 16.30h en Barcelona.
Habrá video streaming: http://bambuser.com/channel/CivilSC. Lugar: Sala William J. Mitchell. Edificio MediaTic. Carrer Roc Boronat 117, 7ª planta. Barcelona.
Estaré presentando la investigación PageOneX: nuevos enfoques en el análisis de portadas de periódicos. Será un recorrido por la historia del análisis de periódicos y portadas de prensa, así como mostrar y explorar las posibilidades de PageOneX como herramienta para el estudio de la cobertura de movimientos sociales.
PageOneX es un software que facilita la codificación y análisis de noticias en portadas de prensa.

Jueves 18 septiembre
16.00h Presentación
16.20h Sincronización y corporización en el 15M. Testeando la hipótesis de núcleos dinámicos en el 15M. Miguel Aguilera, Universidad de Zaragoza
16.50h. Modelos multicapa, medidas posibles y posibles analogías. >Emanuele Ecozzo, Universidad de Zaragoza.
17.20h. Preguntas.
18.00h. Neurociencia sistémica y tecnopolitica. Xabier Barandiaran, Universidad del País Vasco
18.30h. Aplicación de modelos evolutivos en el análisis de redes de comunicación de gran escala. Ignacio Morer, Universidad de Zaragoza.
19.00h. Preguntas.
Viernes 19 septiembre
16.00h. Jóvenes y comunicación en el #15M: Uso de las herramientas online/offline para obtener información de la #acampadabcn. Ariadna Fernández, Universitat Pompeu Fabra.
16.30h PageOneX: nuevos enfoques en el análisis de portadas de periódicos. Pablo Rey Mazón, Montera34.
17.00h. Preguntas.
18.00h. La emergencia de los movimientos red. Una conversación empírica y multidisciplinar con la teoría de los movimientos sociales. Arnau Monterde, Universitat Oberta de Catalunya.
18.30h. Ecosistema post15M, movimientos en red y poder constituyente. Javier Toret, Universitat Oberta de Catalunya.
19.00h. Preguntas.
Más infomación
This post is the newsletter that is sent to all the subscribers and people at the PageOneX users’ list.
Here is a compilation of all the things related to PageOneX that had happened in the past weeks. From now on, I hope I can make this more often.
There have been good threads on PageOneX recently. I list here some of them:
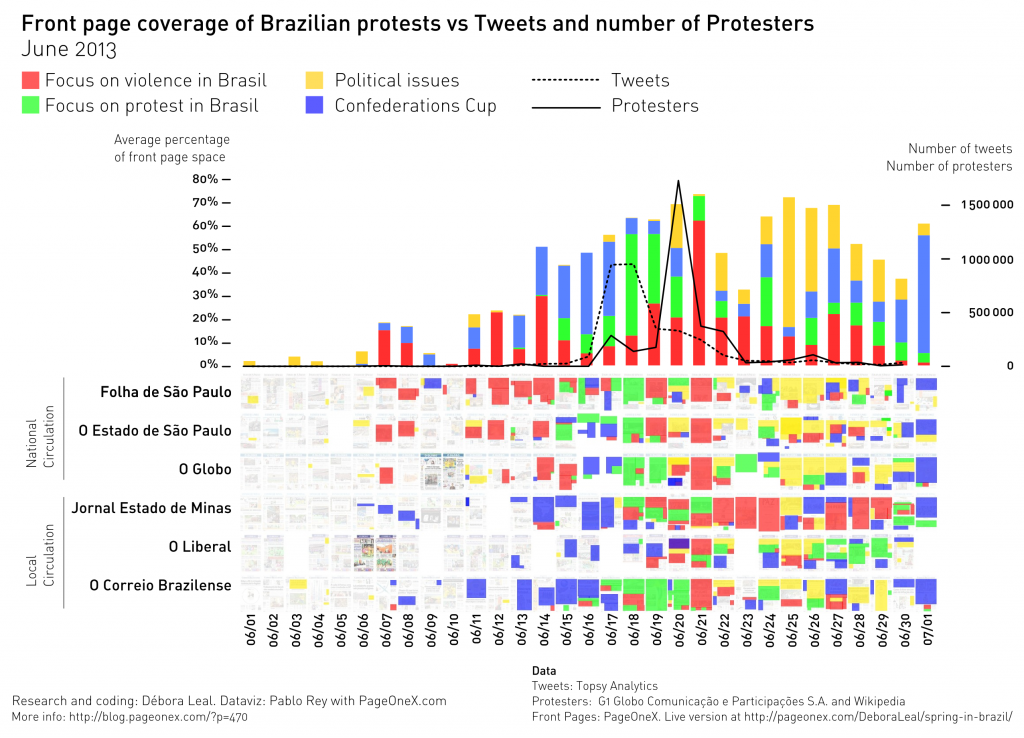
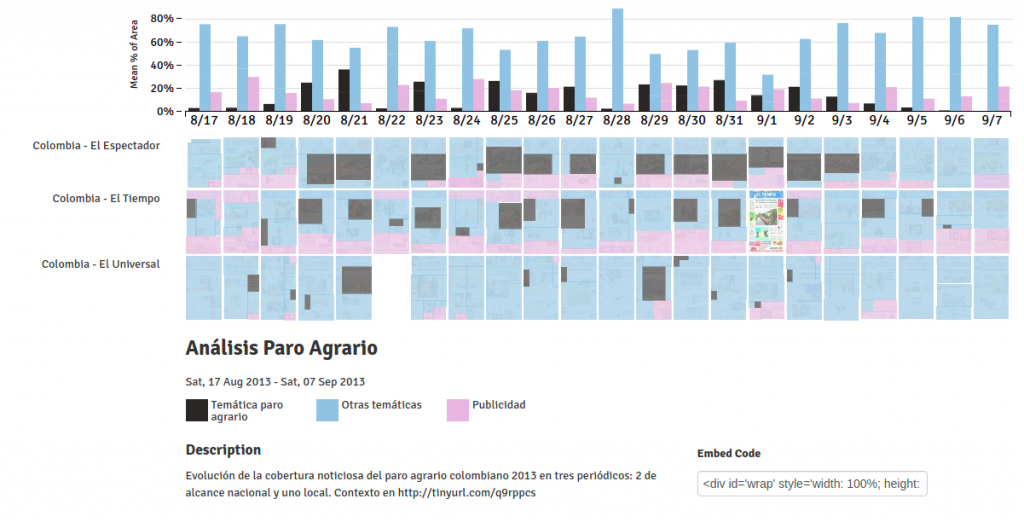
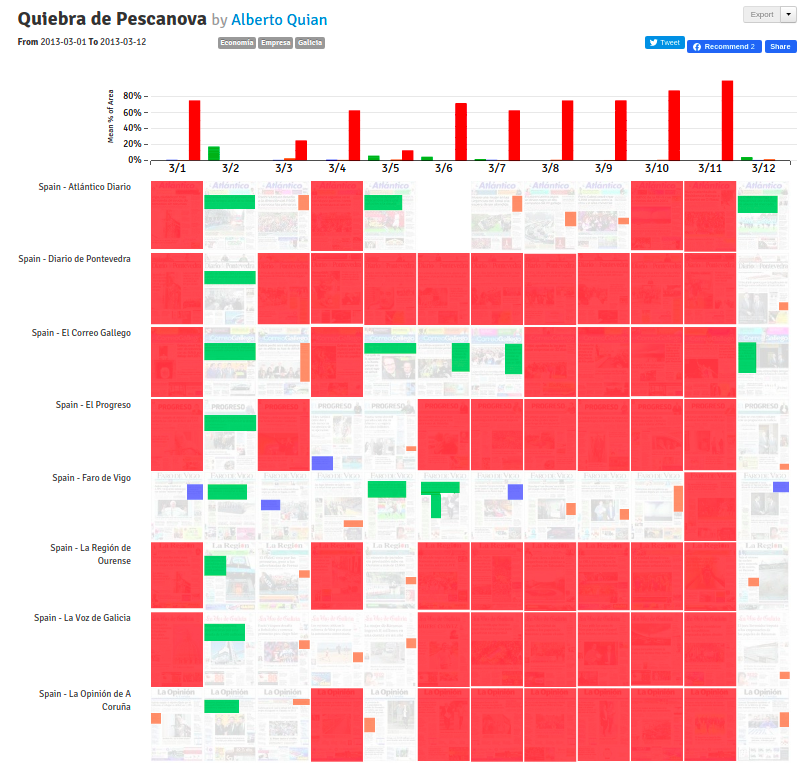
He analyses how the local newspapers from the Galicia, a region in Spain covered the collapse of the food company, debt of €3.6bn. I found interesting how he used the tool: highlighting in red the absence of coverage on the topic, and then classifying by type of heading (importance by h1, h2, h3). The percentage of surface is not useful in this case.
Based in the thread in PageOneX Pescanova.
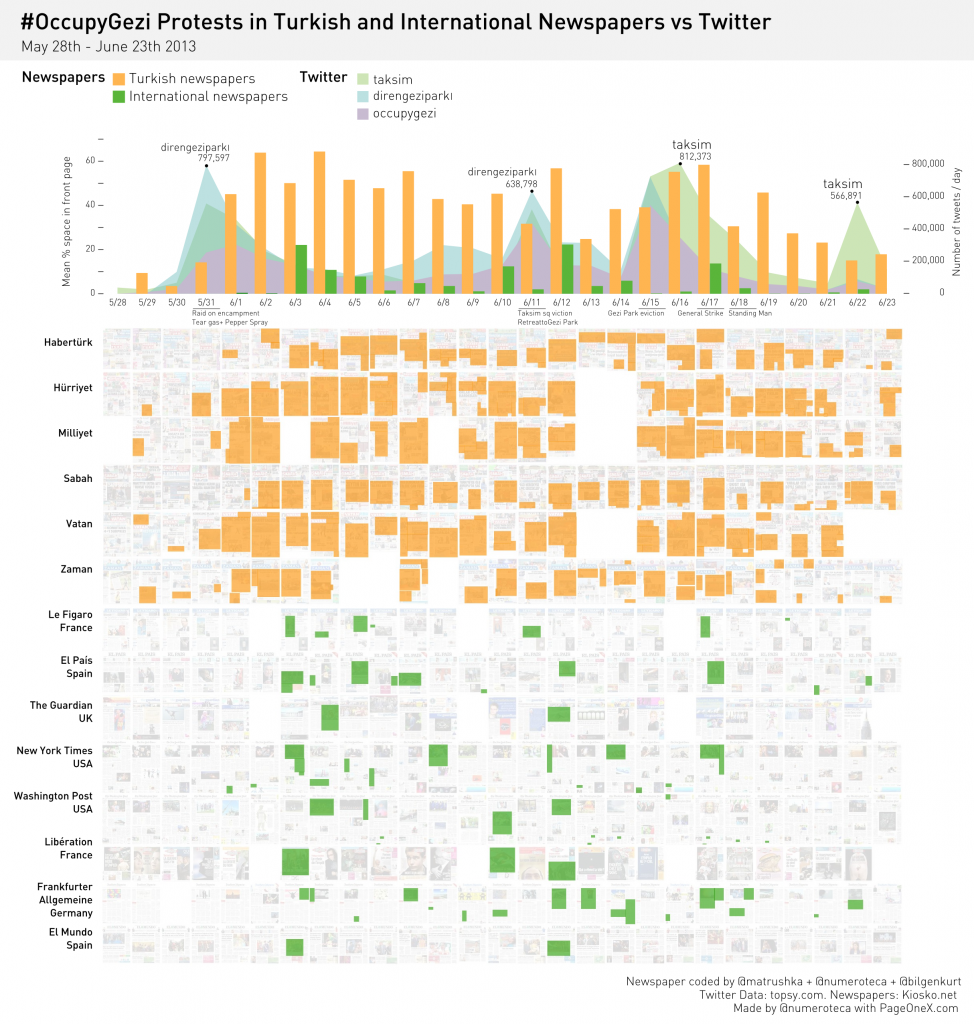
Check the live threads at PageOneX OccupyGezi in International newspapers an OcccupyGezi in Turkish newspapers Coded with @matrushka, @bilgenkurt and @numeroteca.
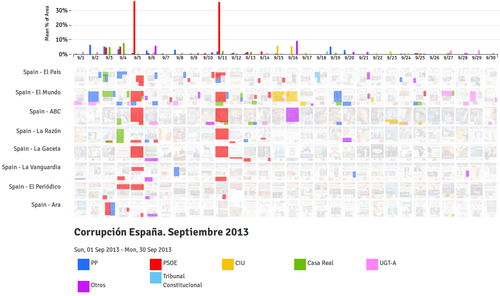
I’ve opened myself a month by month on Spanish corruption coverage. You can check all the threads unter the colorcorrupción category or in the specific Tumblr colorcorrupcion.tumblr.com. Besides the daily analysis, I’ve started a monthly review (September 2013) with more graphics using the export data feature at PageOneX. Last available thread at Corruption in Spain in September 2013.
If you wan to see your thread featured here, just comment this post. There is also a gallery of PageOneX cases at Pinterest.
We changed the license of the code to a GNU AGPL v3, that suits better a web app like PageOneX, after the suggestion by a user related to the GNU project.
Some folks are trying to make their own PageOneX deployment in Heroku or elsewhere. We included an installation guide in the wiki and how to do it in Heroku. thanks to David Cabo for he advice.
There had been a lot of small improvements to make the tool more robust. Check the commits! With Edward L. Platt and Rahul Bhargava, from the Center of Civic Media, we keep fixing bugs.
Coverage of PageOneX: covering the coverage
There was an interesting article/interview in eldiario.es, a Spanish online newspaper, on PageOneX: Analyzing newspaper discourse with free software (Spanish) by @PauLlop.
PageOneX was featured in Euskadi Innova a public website for innovation in the Basque Country.
There was a post on PageOneX for the 6th congress on Research on Information and Communication in Madrid, Spain.
–
Thanks everyone for using PageOneX. It helps us to make it better!