Last January we presented PageOneX to SAGE Concept Grant Application to help us develop some new features. We didn’t get the money, but we thought it would be cool anyway to share with you the proposal. Thanks to Sam Zhang and Fernando Blatt that help us build this proposal.
If you want to help us make a better PageOneX we are now starting a new round of development, a reduced version of all the things that we had originally planned. Join the dev email list and check our road map for the following month.
This was the original proposal:
PageOneX. Visualize attention on newspaper front pages.
Pitch
What it is and the problem it is looking to solve (150 word limit)
PageOneX is a Free Software tool that we designed to simplify the coding, analysis, and visualization of front page newspaper stories and media events. Even as the media ecology has been rapidly transformed by the rise of broadband Internet, mobile phones, and social media, daily print newspapers continue to be a key mechanism for organizing both public and elite attention. Communication scholars have long used column-inches or number of articles of print newspaper coverage as an important indicator of mass media attention. It involved obtaining physical copies of newspapers, coding and measurement by hand, input data into a spreadsheet. PageOneX automates and dramatically simplifies this methodology to enable researchers and media-interested public alike to analyse news coverage with an online tool.
We plan to develop new features to make PageOneX a more robust research tool:
- intercoder reliability
- text-based search (OCR and PDF text extraction)
- cross-platform comparison
Solution
Detailed outline of the product of prototype you are looking to build including visuals (300 word limit)

The PageOneX prototype is up and running, with 1.000+ users. Currently users can easily choose among 700+ newspapers, select a time frame, and highlight parts of newspaper front pages that feature a topic of interest (read our academic article about the tool). PageOneX automatically calculates the area dedicated to a particular topic, automating the process and making it broadly accessible online.
The tool has been used to produce visualizations for multiple peer-reviewed publications (examples at blog.pageonex.com/references).
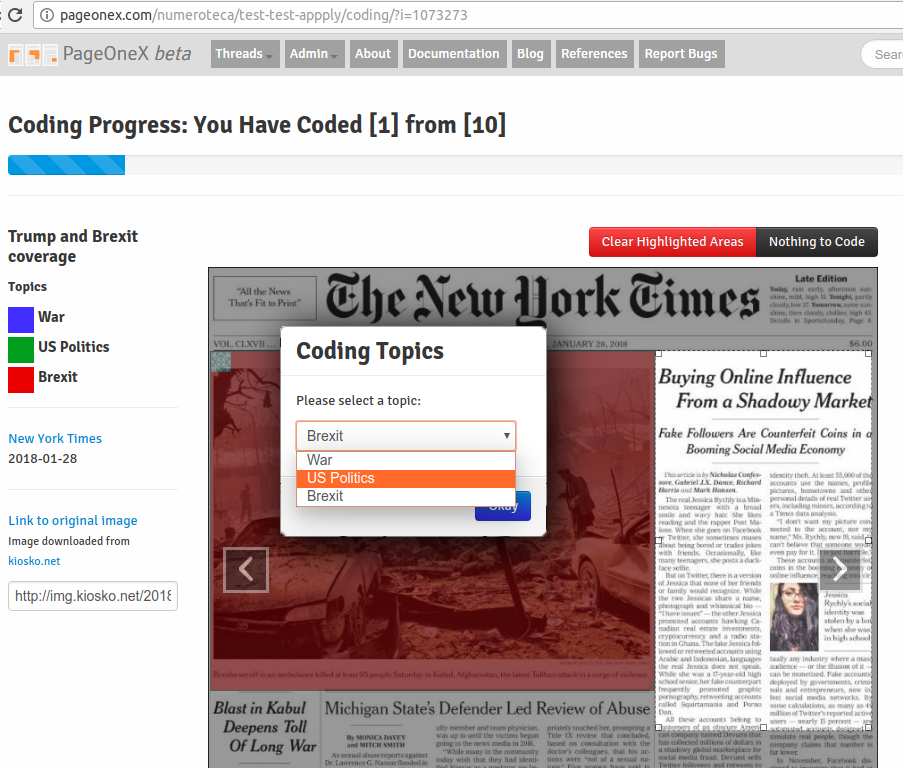
We plan to develop new features to make PageOneX a more robust research tool. Top priority features include:
Intercoder Reliability.
Allow multiple coders to analyse the same set of front pages according to shared coding instructions, without seeing the codes applied by others, then compare values between coders to obtain a statistically valid intercoder reliability measure.
Text-based Search.
No text-based search of newspaper front page content is currently possible. We have identified several possible paths to solve this issue that will enable to analyse data at bigger scale and speed:
- Optical character recognition (OCR),
- Access third-party database of full text newspaper articles such as Lexis-Nexis or MediaCloud,
- Automatic identification of text blocks and layout structure in PDFs.
We are planning to use and base the development in Hadjar, Rigamonti, Lalanne, and Ingold (2004) and a working prototype by Sam Zhang using the Newseum’s database. See: Hadjar, K., Rigamonti, M., Lalanne, D., & Ingold, R. (2004). Xed: A new tool for extracting hidden structures from electronic documents. Proceedings of the First International Workshop on Document Image Analysis for Libraries (212–224). Retrieved from https://diuf.unifr.ch/people/lalanned/Articles/XedDIAL04.pdf
Cross-platform Comparison.
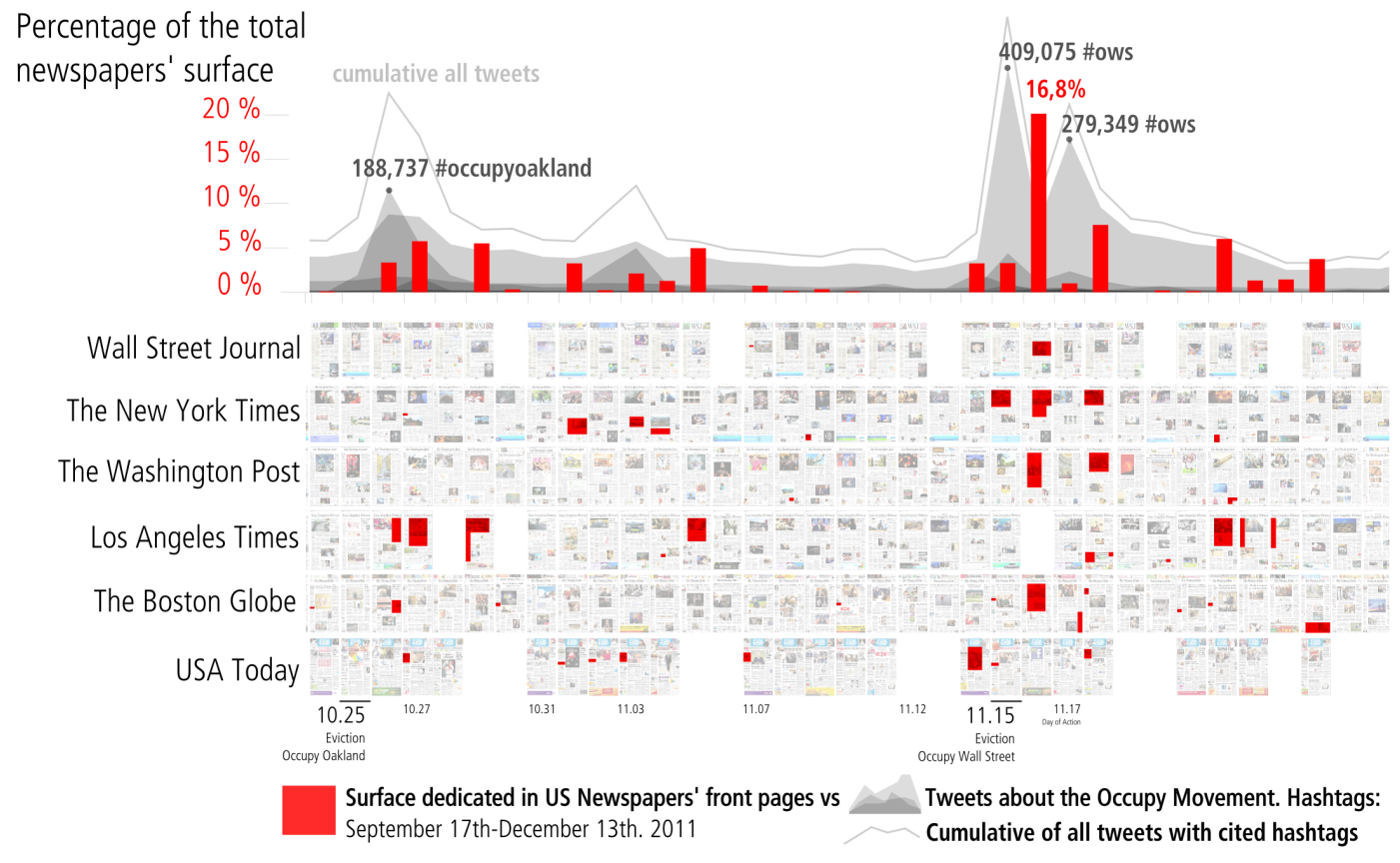
Build comprehensive cross-platform capabilities to produce analysis of media attention, and add statistical analysis of these relationships [For example, Graeff, Stempeck, and Zuckerman (2014) analysed the evolution of a story by using PageOneX alongside other metrics including Twitter updates, Google Search, bit.ly clicks, and more (link)] . We plan to integrate different sources via APIs that increasingly provide access to data: video or audio news broadcasts transcripts, closed captions (Archive.org’s archive of TV news), amount of news (MediaCloud.org) and Twitter.
Diversify Sources of Front Pages.
Currently PageOneX only uses front pages from a single source (kiosko.net). Enabling multiple sources would allow to expand its use.
Additional Feature Requests from Current Users.
Prioritizing outstanding feature requests.
Who wrote the news? News classified by author’s gender.
Website: is there a website associated with the project?
http://pageonex.com/
Competition
What else is out there and why it doesn’t fit the need (200 word limit)
There is no competitor software in the field. Scholars and data journalists who do this kind of analysis of attention on newspaper front pages either use PageOneX, or do manual data collection, coding, and visualization.
In Summer 2014 PageOneX won the 2014 APSA-ITP (American Political Science Association-information technology and politics) award for Best Software.
Schedule
High level outline of your plan for development and who will be working on the product prototype (100 character limit)
April 2018
Set up communication infrastructures, development environment and protocols.
Survey to existing users. Analyse and rank requests.
Update dependencies.
May-July 2018
Intercoder Reliability (IR): development.
Text-based search (TbS): prototype.
Diversify Sources of Front Pages: development and testing.
August-October 2018
TbS: development.
IR: testing.
Cross-platform Comparison (CpC): prototype.
Users’ feature requests: development
November 2018-December 2018
TbS: testing.
CpC: development.
January-February 2019
CpC: testing.
General UX Testing. Bug fixing.
March 2019
Write grant report.
Communication.